Come creare un cluster MySQL multi-nodo su Ubuntu 16.04
Introduzione
Un cluster MySQL è una tecnologia software che fornisce alta disponibilità ed alto throughput. Se si ha già familiarità con altre tecnologie di tipo cluster, troverete i cluster “MySQL Cluster” simili a queste ultime. In breve, vi sono uno o più nodi manager che controllano i data node (i nodi in cui sono memorizzati i dati). Dopo essersi consultato con il nodo manager, il client (client MySQL, server, o API native) si connette direttamente ai data-node.
Ci si potrebbe chiedere come la replicazione MySQL sia legata ai cluster MySQL. Con il cluster non c’è la tipica replica dei dati, ma c’è invece la sincronizzazione dei data node. A questo scopo deve essere utilizzato un motore di dati speciale: NDBCluster (NDB). Pensate al cluster come ad un unico ambiente logico MySQL con componenti ridondanti. In questo modo, un cluster MySQL può partecipare alla replicazione con altri cluster MySQL.
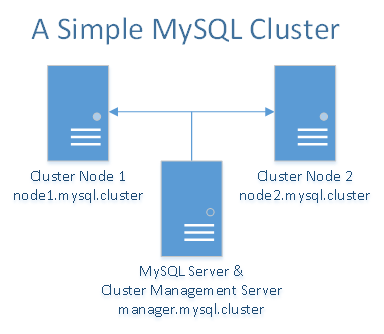
Un cluster MySQL funziona meglio in un ambiente “per niente condiviso”. Idealmente, due componenti non dovrebbero condividere lo stesso hardware. Per semplicità e a scopo dimostrativo, ci limitiamo ad usare solo tre Droplet [la VPS di DigitalOcean, NdT]. Ci saranno due Droplet che agiscono come data node che attuano la sincronizzazione dei dati tra di loro. La terza Droplet sarà utilizzata per il cluster manager e allo stesso tempo per i server/client MySQL. Se si dispone di più Droplet è possibile aggiungere più data node, separare il cluster manager dai server/client MySQL e aggiungere anche più Droplet per i cluster manager e per i server/client MySQL.
Prerequisiti
Avrete bisogno di un totale di tre Droplet: una per il manager del cluster MySQL e per il server ed client MySQL e due per i data node MySQL ridondanti.
Nello stesso data center di DigitalOcean, create le seguenti Droplet con rete privata abilitata:
- Tre Droplet Ubuntu 16.04 con un minimo di 1 GB di RAM e reti private abilitate
- Utente non root con privilegi sudo per ogni Droplet (la Configurazione iniziale del server con Ubuntu 16.04 spiega come impostare questa funzione)
Un cluster MySQL conserva un sacco di informazioni in RAM. Ogni Droplet dovrebbe avere almeno 1 GB di RAM.
Come accennato nel tutorial sul private networking, assicuratevi di impostare dei record personalizzati per le 3 Droplet. Per ragioni di semplicità e comodità, nel file /etc/hosts useremo i seguenti record, personalizzati per ogni Droplet:
10.XXX.XX.X node1.mysql.cluster
10.YYY.YY.Y node2.mysql.cluster
10.ZZZ.ZZ.Z manager.mysql.cluster
Sostituite di conseguenza gli IP evidenziati con gli IP privati delle vostre Droplet.
Salvo diversamente specificato, tutti i comandi di questo tutorial che richiedono privilegi di root dovrebbero essere eseguiti come utente non root con privilegi sudo.
Fase 1 – Download ed installazione di MySQL Cluster
Al momento della stesura di questa guida, l’ultima versione GPL di MySQL Cluster è la 7.4.11. Il prodotto si basa su MySQL 5.6 e comprende:
- Il software del cluster manager
- Il software per la gestione dei data node
- I binari del server e del client MySQL 5.6
È possibile scaricare la versione libera di MySQL Cluster, generalmente disponibile (GA, Generally Available) dalla pagina ufficiale per il download di MySQL Cluster. Da questa pagina scegliete il pacchetto per la piattaforma Debian Linux, che è adatto anche per Ubuntu. Assicuratevi inoltre di selezionare la versione a 32 o a 64 bit a seconda dell’architettura della vostra Droplet. Caricate il pacchetto di installazione per ognuna delle vostre Droplet.
Le istruzioni di installazione saranno le stesse per tutte le Droplet, in modo da completare la procedura su tutte e 3.
Prima di iniziare l’installazione deve essere installato il pacchetto libaio1, dal momento che è una dipendenza:
$ sudo apt-get install libaio1Dopo di che installate il pacchetto MySQL Cluster:
$ sudo dpkg -i mysql-cluster-gpl-7.4.11-debian7-x86_64.deb Ora potete trovare l’installazione di MySQL Cluster nella directory /opt/mysql/server-5.6/. Lavoreremo soprattutto con la directory bin (/opt/mysql/server-5.6/bin/), dove si trovano tutti i binari.
La stessa procedura di installazione deve essere eseguita su tutte e tre le Droplet a prescindere dal fatto che ognuna avrà differenti funzioni: manager o data node.
Successivamente, si configurerà il cluster manager su ogni Droplet.
Fase 2 – Configurazione ed avvio del cluster manager
In questa fase configureremo il cluster manager ( manager.mysql.cluster ). La sua corretta configurazione garantirà la giusta sincronizzazione e la giusta distribuzione del carico tra i data node. Tutti i comandi devono essere eseguiti sulla Droplet manager.mysql.cluster.
Il cluster manager è il primo componente che deve essere avviato in ogni cluster. Ha bisogno di un file di configurazione che viene passato come argomento al suo file binario. Per comodità, per la sua configurazione useremo il file /var/lib/mysql-cluster/config.ini.
Sulla Droplet manager.mysql.cluster create prima la directory in cui il file risiede (/var/lib/mysql-cluster):
$ sudo mkdir /var/lib/mysql-cluster Quindi create un file e modificatelo con nano:
$ sudo nano /var/lib/mysql-cluster/config.iniTale file deve contenere il seguente codice:
/var/lib/mysql-cluster/config.ini
[ndb_mgmd]
# Opzioni del processo manager:
hostname=manager.mysql.cluster # Hostname del manager
datadir=/var/lib/mysql-cluster # Directory per i file di log
[ndbd]
hostname=node1.mysql.cluster # Hostname del primo data node
datadir=/usr/local/mysql/data # Directory remota per i file di dati
[ndbd]
hostname=node2.mysql.cluster # Hostname del secondo data node
datadir=/usr/local/mysql/data # Directory remota per i file di dati
[mysqld]
# Opzioni del nodo SQL:
hostname=manager.mysql.cluster # Nel nostro casi i server/client MySQL sono sulla stessa Droplet del cluster manager Per ciascuna delle componenti di cui sopra è stato definito un parametro hostname. Si tratta di una misura di sicurezza importante perché solo all’host specificato sarà consentito di connettersi al manager e a partecipare al gruppo in base al ruolo destinatogli.
Inoltre, i parametri hostname specificano su quale interfaccia verrà eseguito il servizio. Questo è importante, ed è importante per la sicurezza, perché nel nostro caso i nomi degli host qui sopra puntano agli indirizzi IP privati che abbiamo specificato nel file /etc/hosts. Dunque non è possibile accedere ai servizi di cui sopra al di fuori della rete privata.
Nel file soprastante è possibile aggiungere più componenti ridondanti, come data node (ndbd) o server MySQL (mysqld) semplicemente definendo le istanze aggiuntive esattamente nello stesso modo.
Ora è possibile avviare il manager per la prima volta eseguendo il binario ndb_mgmd e specificando il file di configurazione con l’argomento -f, in questo modo:
$ sudo /opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.iniDovreste vedere un messaggio sul corretto avvio, simile a questo:
Output di ndb_mgmd
MySQL Cluster Management Server mysql-5.6.29 ndb-7.4.11 Probabilmente vorreste che il servizio manager sia avviato automaticamente al boot del server. La release GA del cluster non viene fornita con uno script di avvio adatto, ma ce ne sono un paio disponibili online. Per iniziare, si può semplicemente aggiungere il comando di avvio al file /etc/rc.local ed il servizio verrà avviato automaticamente durante il boot. Prima però dovreste fare in modo che /etc/rc.local venga eseguito durante l’avvio del server. Su Ubuntu 16.04 ciò richiede l’esecuzione di un comando aggiuntivo:
$ sudo systemctl enable rc-local.service Aprite quindi il file /etc/rc.local per effettuare la modifica:
$ sudo nano /etc/rc.local Aggiungete il comando di avvio prima della linea exit come di seguito:
/etc/rc.local
...
/opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.ini
exit 0Salvate e chiudete il file.
Il cluster manager non deve essere in esecuzione per tutto il tempo. Può essere avviato, arrestato e riavviato senza che porti tempi di inattività al cluster. È necessario solo durante lo startup iniziale dei nodi del cluster e dei server/client MySQL.
Fase 3 – Configurazione ed avvio dei data node
Di seguito configureremo i data node (node1.mysql.cluster e node2.mysql.cluster) per memorizzare i file dei dati e per supportare adeguatamente il motore NDB. Tutti i comandi devono essere eseguiti su entrambi i nodi. Si può iniziare prima con node1.mysql.cluster e ripetere esattamente la stessa procedura su node2.mysql.cluster.
I data node leggono la configurazione dal file di configurazione standard di MySQL (/etc/my.cnf) e più precisamente la parte dopo la linea [mysql_cluster]. Create questo file con nano e modificatelo:
$ sudo nano /etc/my.cnfSpecificate il nome host del manager in questo modo:
/etc/my.cnf
[mysql_cluster]
ndb-connectstring=manager.mysql.clusterSalvate e chiudete il file.
Specificare la posizione del manager è l’unica configurazione necessaria per avviare il motore del nodo. Il resto della configurazione sarà preso direttamente dal manager. Nel nostro esempio, il data node troverà che la sua directory dei dati è /usr/local/mysql/data come per la configurazione del manager. Questa directory deve essere creata sul nodo. Lo si può fare con il comando:
$ sudo mkdir -p /usr/local/mysql/dataDopo di che si può avviare il data node per la prima volta con il comando:
$ sudo /opt/mysql/server-5.6/bin/ndbdDopo un avvio riuscito, dovreste vedere un output simile a:
Output di ndbd
2016-05-11 16:12:23 [ndbd] INFO -- Angel connected to 'manager.mysql.cluster:1186'
2016-05-11 16:12:23 [ndbd] INFO -- Angel allocated nodeid: 2Ora il servizio ndbd dovrebbe avviarsi automaticamente con il server. La versione GA del cluster non viene fornita nemmeno con uno script di avvio adatto a ciò. Proprio come abbiamo fatto per il cluster manager, aggiungiamo il comando di avvio al file /etc/rc.local. Anche in questo caso, si dovrà fare in modo che /etc/rc.local venga eseguito durante l’avvio del server con il comando:
$ sudo systemctl enable rc-local.service Aprite dunque il file /etc/rc.local per la modifica:
$ sudo nano /etc/rc.local Aggiungete il comando di avvio prima della linea exit in questo modo:
/etc/rc.local
...
/opt/mysql/server-5.6/bin/ndbd
exit 0Salvate e chiudete il file.
Una volta che avete finito con il primo nodo, ripetete esattamente la stessa procedura sull’altro nodo, che nel nostro esempio è node2.mysql.cluster.
Fase 4 – Configurazione ed avvio del server e del client MySQL
Un server MySQL standard, come quello che è disponibile nel repository apt di default su Ubuntu, non supporta il cluster engine NDB per MySQL. È per questo che avete bisogno dell’installazione di un server MySQL personalizzata. Per di più, il pacchetto cluster che abbiamo già installato sulle tre Droplet è dotato di un server MySQL e di un client. Come già accennato, useremo il server MySQL ed il client sul nodo manager (manager.mysql.cluster ).
La configurazione viene memorizzata di nuovo nel file di default /etc/my.cnf. Su manager.mysql.cluster aprite il file di configurazione:
$ sudo nano /etc/my.cnfAggiungeteci quanto segue:
/etc/my.cnf
[mysqld]
ndbcluster # avvia il motore di storage NDB
... Come da buona prassi, il server MySQL deve essere eseguito con il proprio utente ( mysql), che appartiene al proprio gruppo (di nuovo, mysql). Dunque creiamo prima il gruppo:
$ sudo groupadd mysql$ sudo useradd -r -g mysql -s /bin/false mysql Quindi create l’utente mysql appartenente a questo gruppo e assicuratevi che non possa utilizzare la shell impostando il suo percorso di shell a /bin/false in questo modo:
$ sudo useradd -r -g mysql -s /bin/false mysqlL’ultimo requisito per l’installazione del server MySQL fatto su misura è quello di creare il database predefinito. Lo si può fare con il comando:
$ sudo /opt/mysql/server-5.6/scripts/mysql_install_db --user=mysql
Per avviare il server MySQL useremo lo script di avvio da /opt/mysql/server-5.6/support-files/mysql.server. Copiatelo nella directory degli script di init di default con il nome di mysqld in questo modo:
$ sudo cp /opt/mysql/server-5.6/support-files/mysql.server /etc/init.d/mysqldAttivate lo script di avvio e aggiungetelo ai runlevel predefiniti con il comando:
$ sudo systemctl enable mysqld.serviceOra siamo in grado di avviare il server MySQL per la prima volta, manualmente, con il comando:
$ sudo systemctl start mysqld Come client MySQL useremo di nuovo il binario personalizzato che viene fornito con l’installazione del cluster. Ha il seguente percorso: /opt/mysql/server-5.6/bin/mysql. Per comodità creiamo un link simbolico ad esso nel percorso di default /usr/bin:
$ sudo ln -s /opt/mysql/server-5.6/bin/mysql /usr/bin/ Ora è possibile avviare il client dalla riga di comando semplicemente digitando mysql in questo modo:
$ mysqlSi dovrebbe vedere un output simile a:
Output di ndb_mgm
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.6.29-ndb-7.4.11-cluster-gpl MySQL Cluster Community Server (GPL) Per uscire dal prompt di MySQL è sufficiente digitare quit o premere contemporaneamente CTRL-D.
Quanto sopra è la prima verifica che mostra che il cluster MySQL, il server ed il client sono in esecuzione. Successivamente passeremo attraverso test più dettagliati per confermare il funzionamento corretto del cluster.
Test del cluster
A questo punto il nostro semplice cluster MySQL con un client, un server, un manager e due data node dovrebbe essere completo. Dalla Droplet con il cluster manager (manager.mysql.cluster ) aprite la console di gestione con il comando:
$ sudo /opt/mysql/server-5.6/bin/ndb_mgmOra il prompt dovrebbe passare alla console del cluster manager. Ecco come si presenta:
All'interno della console ndb_mgm
-- NDB Cluster -- Management Client --
ndb_mgm> Una volta all’interno della console eseguite il comando SHOW in questo modo:
ndb_mgm> SHOWSi dovrebbe vedere un output simile a questo:
Output di ndb_mgm
Connected to Management Server at: manager.mysql.cluster:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @10.135.27.42 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0, *)
id=3 @10.135.27.43 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)
[mysqld(API)] 1 node(s)
id=4 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)Quanto sopra dimostra che ci sono due data node con ID 2 e 3. Sono attivi e connessi. Vi è anche un nodo di gestione con id 1 ed un server MySQL con id 4. È possibile trovare ulteriori informazioni su ogni ID digitandone il numero con il comando STATUS in questo modo:
ndb_mgm> 2 STATUSIl comando qui sopra dovrebbe mostrare lo stato del nodo 2 con le sue versioni di MySQL e NDB:
Output di ndb_mgm
Node 2: started (mysql-5.6.29 ndb-7.4.11) Per uscire dalla console del manager digitate quit.
La console del manager è molto potente ed offre molte altre opzioni per la gestione del cluster e dei suoi dati, compresa la creazione di un backup online. Per ulteriori informazioni consultate la documentazione ufficiale.
Ora facciamo una prova con il client MySQL. Dalla stessa Droplet, avviate il client con il comando mysql per l’utente root di MySQL. Ricordatevi che in precedenza gli abbiamo creato un link simbolico.
$ mysql -u rootLa console passerà alla console del client MySQL. Una volta all’interno del client MySQL, eseguite il comando:
mysql> SHOW ENGINE NDB STATUS \GOra si dovrebbero vedere tutte le informazioni riguardanti l’avvio del motore NDB del cluster, con i dettagli della connessione:
Output di mysql
*************************** 1. row ***************************
Type: ndbcluster
Name: connection
Status: cluster_node_id=4, connected_host=manager.mysql.cluster, connected_port=1186, number_of_data_nodes=2, number_of_ready_data_nodes=2, connect_count=0
... Potreste provare a spegnere un data node al fine di testare la stabilità del cluster. La cosa più semplice sarebbe riavviare semplicemente tutta la Droplet in modo da avere un test completo del processo di recovery. Si vedrà il valore di number_of_ready_data_nodes cambiare in 1 e tornare di nuovo a 2 nel momento in cui il nodo viene riavviato.
Lavorare con il motore NDB
Per vedere come il cluster funziona davvero, creiamo una nuova tabella con il motore NDB e inseriamoci alcuni dati. Si noti che per poter utilizzare la funzionalità cluster, il motore deve essere NDB. Se si utilizza InnoDB (quello di default) o qualsiasi altro motore diverso da NDB, non sarà possibile fare uso di cluster.
In primo luogo, creiamo un database chiamato cluster con il comando:
mysql> CREATE DATABASE cluster;Poi passiamo al nuovo database:
mysql> USE cluster; Ora, create una semplice tabella chiamata cluster_test in questo modo:
mysql> CREATE TABLE cluster_test (name VARCHAR(20), value VARCHAR(20)) ENGINE=ndbcluster; Qui sopra abbiamo esplicitamente specificato il motore ndbcluster per usufruire del cluster. Possiamo quindi iniziare l’inserimento dei dati con una query come questa:
mysql> INSERT INTO cluster_test (name,value) VALUES('some_name','some_value');Per verificare se i dati sono stati inseriti, eseguite una query come questa:
mysql> SELECT * FROM cluster_test;Quando si stanno inserendo e selezionando i dati in questo modo, si sta effettuando un load balancing (bilanciamento del carico) delle query su tutti data node disponibili, che nel nostro esempio sono due. Con questa scalabilità potrete avere un beneficio sia in termini di stabilità che di prestazioni.
Conclusioni
Come abbiamo visto in questo articolo, la creazione di un cluster MySQL può essere semplice e facile. Naturalmente ci sono soluzioni molto più avanzate ed aspetti che vale la pena di padroneggiare prima di mettere il cluster nell’ambiente di produzione. Come sempre, assicuratevi di avere una adeguata procedura di test, perché in seguito alcuni problemi potrebbero essere molto difficili da risolvere. Per maggiori informazioni e ulteriori approfondimenti andate alla documentazione ufficiale MySQL Cluster.
Autore: Anatoliy Dimitrov
Revisore: Tammy Fox
Traduzione dell’articolo: https://www.digitalocean.com/community/tutorials/how-to-create-a-multi-node-mysql-cluster-on-ubuntu-16-04 Copyright © 2016 DigitalOcean™ Inc.
